
Introduction
Fuzzing is an automated software testing technique used primarily to uncover bugs and security vulnerabilities in software. It involves generating many genuine, random, semi-random and faulty inputs to a software program to crash or behave unexpectedly. Here are few key aspects of fuzzing:
- Random Input Generation: Fuzzers generate unexpected, random, or malformed inputs that a typical user might not think of. This input can reveal edge cases that were not considered during the development process.
- Bug Detection: By observing how the program handles these inputs, developers can identify and fix errors that might lead to crashes, buffer overflows, memory leaks, or other types of vulnerabilities.
- Automation: Fuzzing is highly automated, allowing it to test thousands to millions of input cases over a short period of time. This automation makes it an effective way to test robustness and security without too much manual intervention by the tester.
Types of Fuzzing:
- Black-box Fuzzing: The fuzzer has no knowledge of the programs internal structure and treats the software as a black box, exploring inputs to find errors or unexpected results.
- White-box Fuzzing: This involves knowledge of the program’s source code or binary to guide the input generation process, usually employing techniques like symbolic execution.
- Grey-box Fuzzing: Combines elements of both black-box and white-box fuzzing by having partial knowledge of the internal structures, often using instrumentation to monitor the program execution.
AFL++
AFL++ (American Fuzzy Lop Plus Plus) is an enhanced version of the original AFL (American Fuzzy Lop) fuzzing tool developed by lcamtuf, which is widely recognized in the security and software development communities for its effectiveness in finding bugs and security vulnerabilities through automated input generation. AFL++ includes a range of improvements and new features designed to make fuzzing more efficient and adaptable. Here are some key aspects of AFL++:
- Enhanced Performance and Usability AFL++ has been developed with performance optimizations and usability improvements over the original AFL. It includes better scheduling algorithms, enhanced handling of the fuzzing queue, and refined instrumentation techniques.
- Extended Functionality: The tool incorporates additional features like more powerful mutators, and improved handling of crashes, and support for new types of targets and environments, such as those not originally well-supported by AFL.
- Community-Driven Development: AFL++ is maintained and enhanced by a community of developers, ensuring that it stays up to date with the latest technology and techniques in fuzzing technology and security testing.
- Open Source: Just like the original AFL, AFL++ is open source, allowing users to modify, improve, and distribute the software in accordance with its licensing terms. This openness promotes widespread adoption and continuous enhancement from the global and software development communities.
Setting up our environment
Setting up AFL++ is rather straightforward but involves installing several properly installed and configured packages. This guide will walk you through setting up AFL++ on an Ubuntu 24.04 LTS or later:
- Update your system: Before installing any new software, its a good idea to update your system. Open a terminal and executing the following commands:
sudo apt update && sudo apt upgrade -y- Install dependencies: AFL++ required a few packages to be installed on your system. You can install these dependencies with the following command:
sudo apt install -y build-essential gcc g++ make cmake python3-dev python3-pip git llvm clang- Install AFL++: Clone the AFL++ repo from GitHub and compile it:
git clone https://github.com/AFLplusplus/AFLplusplus.git
cd AFLplusplus
make
sudo make install- Post-installation configuration: To ensure AFL++ can work correctly, we need to make some system modifications, please note that these changes are only temporarily, and your system will go back to its default setting after you reboot your machine:
sudo su
echo core >/proc/sys/kernel/core_pattern
cd /sys/devices/system/cpu
echo performance | tee*/cpufreq/scaling_governorFuzzing with AFL++
Now that we have the boring stuff out of the way, we can finally start fuzzing, but for that we need a target. We will use EasyEXIF which is a:
A tiny ISO-compliant C++ EXIF parsing library. EasyEXIF is a tiny, lightweight C++ library that parses basic information out of JPEG files. It uses only the std::string library and is otherwise pure C++. You pass it the binary contents of a JPEG file, and it parses several of the most important EXIF fields for you.
Seems straight forward enough, so lets go ahead and set the program up ready for fuzzing:
- Clone the repo: *insert funny and educational text here xD*
git clone https://github.com/mayanklahiri/easyexif.git- Modify the Makefile: By default, the program will be compiled without any instrumentation, rendering it useless for our purposes, so lets change the Makefile:
# Change the CXX
CXX=afl-clang-fast++
make- Compile the source code: We’ll use afl-clang-fast++, a helper application which serves as a drop-in replacement for clang, used to recompile third-party code with the required runtime instrumentation for afl-fuzz
makeThe program compiles without any issues and you should see the following output:
afl-clang-fast++ -O2 -pedantic -Wall -Wextra -ansi -std=c++11 -c exif.cpp
afl-cc++4.21a by Michal Zalewski, Laszlo Szekeres, Marc Heuse - mode: LLVM-PCGUARD
SanitizerCoveragePCGUARD++4.21a
[+] Instrumented 415 locations with no collisions (non-hardened mode) of which are 24 handled and 0 unhandled selects.
afl-clang-fast++ -O2 -pedantic -Wall -Wextra -ansi -std=c++11 -o demo exif.o demo.cpp
afl-cc++4.21a by Michal Zalewski, Laszlo Szekeres, Marc Heuse - mode: LLVM-PCGUARD SanitizerCoveragePCGUARD++4.21a
[+] Instrumented 55 locations with no collisions (non-hardened mode) of which are 0 handled and 0 unhandled selects.As a bonus, afl-clang-fast++ will allow AFL++ to execute the binary in rapid succession – much faster if we were to compile it using other methods.
- Folder structure & test cases: AFL++ needs 2 directories, one where we will store our test cases (data that will be used by AFL++ to fuzz the binary with) and an output folder:
mkdir in
mkdir out- Downloading sample images: Our binary needs JPEG images, lets download a several test images
cd in
wget filesamples.com/samples/image/jpeg/sample_640%C3%97426.jpeg
wget filesamples.com/samples/image/jpeg/sample_1280%C3%97853.jpeg
wget filesamples.com/samples/image/jpeg/sample_1920%C3%971280.jpeg
wget filesamples.com/samples/image/jpeg/sample_5184%C3%973456.jpeg- Let’s rock ‘n roll: We are all ready, so lets fire up afl-fuzz and start fuzzing
cd ..
afl-fuzz -i in -o out ./demo @@AFL++ will start fuzzing the binary and you should see a screen that looks like this
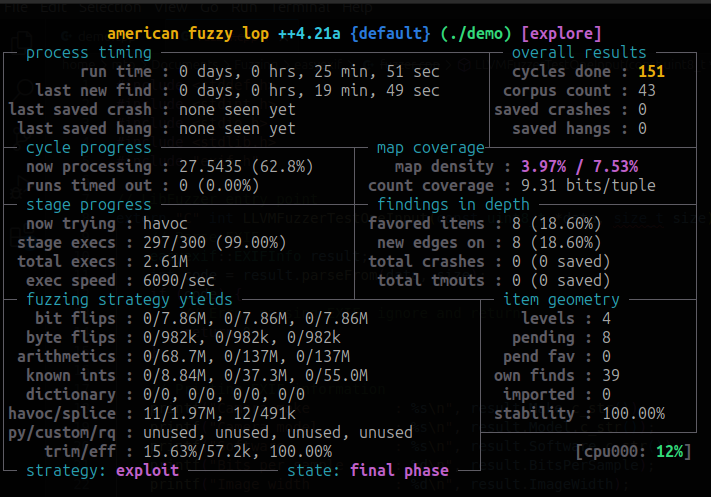
What’s insane is that AFL++ can execute the binary 6090 times per second. This process requires no user interaction, so you are free to do other things and come back in about 30 minutes to see how AFL++ is doing.
To my not so big surprise, AFL++ was unable to find any crashes and this can be because:
- The program is safe and contains no bugs.
- Our test cases are in fact not good enough.
Accepting the first option is literally accepting defeat. So, let’s go back to the drawing board so we can arm ourselves with a new strategy.
If you’re familiar with the rubber ducky technique, so lets explain to our little friend what we have done so far:
- Compiled the program with afl-clang-fast++
- Gave the program a bunch of JPEG files
- The program was doing what it was designed to do
- We entered the void of sadness and disappointment
It should be clear by now; we didn’t provide the program with… faulty and corrupted JPEG images.
Spreading corruption throughout the land
Corrupted JPEG files that have become damaged or altered in a way that prevents them from being properly displayed or processed – the key here is processed. Corruption can occur due to a variety of reasons, including:
- File Transfer Errors: Errors can happen during the process of transferring the files between storage devices, the network, or over the internet, which may lead to incomplete or faulty files.
- Storage Media Issues: Problems with the storage media, such as a hard drive failure, bad sectors, or physical damage to the storage media, can corrupt files saved on the device.
- Software Bugs: Bugs in software that creates, edits, or manages JPEG files can introduce errors into the files, leading to corruption.
- Improper Editing: Improperly editing or saving JPEG files with unsuitable software can also cause corruption.
- Virus or Malware Attacks: Hide your kids, hide your wives as viruses or other malicious software can intentionally or unintentionally corrupt JPEG files.
When a JPEG file is corrupted, it might not open at all, or it might display incorrectly, showing strange colors, patterns, or only partially rendering. The severity of the corruption and the parts of the file data that have been altered determine what symptoms will appear.
Being the 90s kid that I am, I have seen my fair share of faulty images preventing me from seeing the juicy details I was hoping to see (stop giggling). Lets download a few deliberately corrupted images:
cd in
wget upload.wikimedia.org/wikipedia/commons/6/66/Example_snapshot_of_corrupted_image.jpg
wget https://upload.wikimedia.org/wikipedia/commons/thumb/9/9a/JPEG_Corruption.jpg/800px-JPEG_Corruption.jpgArmed with corruption, we can fire up AFL++ and wait for results
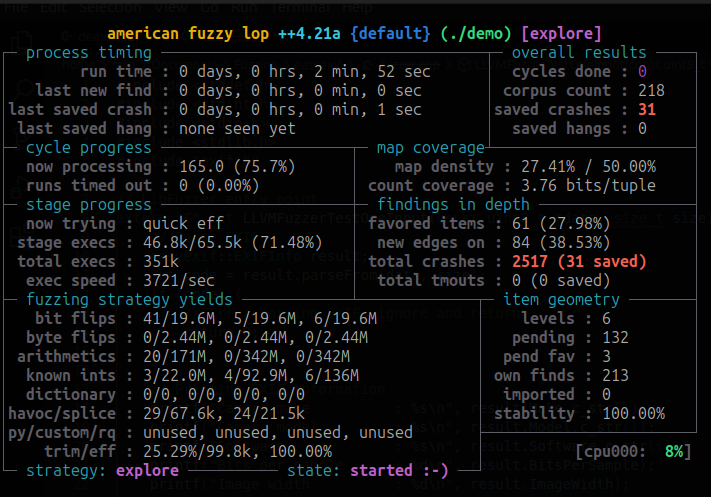
It took AFL++ about a minute to crash the binary, so lets have even more fun and wait to see how many crashes AFL++ can produce.
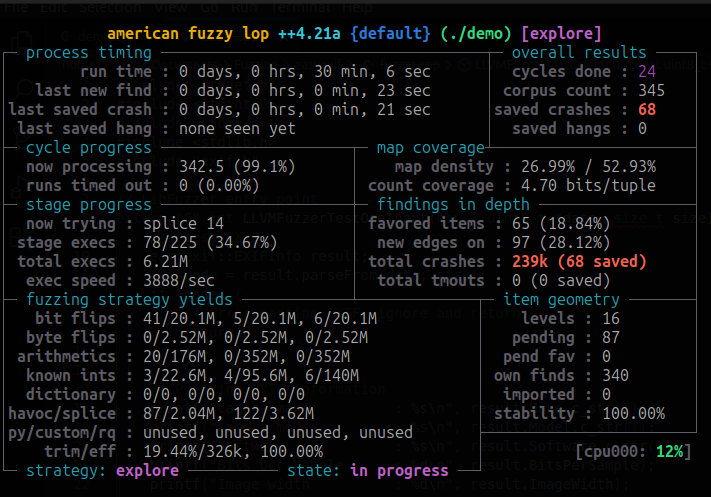
In 30 minutes or so, AFL++ was able to execute the binary more than 6 million times, produce 345 test cases, complete 24 cycles, and crash the binary 68 times. That’s awesome!
Triage the crash
Triaging a crash refers to the process of analyzing and prioritizing the crashes discovered by the fuzzer. This process is essential to determine the cause, severity, and potential impact of each crash. Here’s how triaging typically works:
- Identify the Crash: First, confirm that the crash is real and reproducible. This involves ensuring that the crash happens consistently under the same conditions or with the same inputs.
- Analyze the Crash: Examine the crash details, such as the stack trace, memory dumps, and logs to understand where and why the crash occurred. This might involve using debugging tools, such as GDB, to inspect the state of the program at the time of the crash. This is out of the scope for this blogpost, but we will look at this in the future, so keep an eye out for that 😉
- Classify the Severity: Determine the severity of the crash based on factors like whether it leads to a DoS, memory leakage, unauthorized access, code execution, or other harmful (and awesome) outcomes. This helps in prioritizing which crashes to address first.
- Assess Exploitability: Evaluate how exploitable the crash is in terms of being used by an attacker to compromise a system. This includes checking if the crash could potentially lead to arbitrary code execution or escalation of privileges (now thats awesome).
- Document and Report: Document the findings and, if necessary, report them to the relevant stakeholders, which could include internal development teams, software vendors, or even publicly if it’s related to open-source software (as it is here the case), and the issue needs broader awareness. You might get rewarded in the process, contribute to making the internet a safer place, boost your career as having a CVE to your name will boost your resume, and help you pass the infamous HR filter.
Conclusion
Fuzzing stands as a cornerstone in the domain of cybersecurity due to its unmatched efficacy in pre-emptively identifying vulnerabilities that might otherwise remain undetected until exploited by malicious entities. By automatically injecting a multitude of unpredictable inputs into software systems, fuzzing uncovers hidden bugs and security flaws that standard testing methods might overlook. This proactive approach to security testing enables developers to fortify their applications against potential attacks, thus significantly reducing the risk of security breaches. Moreover, as cyber threats continue to evolve in complexity and stealth, fuzzing’s role becomes even more critical, providing a dynamic and adaptable defense mechanism that keeps pace with emerging vulnerabilities. Ultimately, the integration of fuzzing into the cybersecurity strategy not only enhances the robustness of digital infrastructures but also upholds the integrity and trustworthiness of technology in an increasingly interconnected world.